
Essentiële Vaardigheden voor Succesvolle Inkopers: Menselijk Inzicht en Datagebruik
Om een succesvol inkoper te zijn, moet je in mijn ogen aan minstens twee dingen voldoen. Ten eerste is het menselijke aspect heel erg belangrijk. Als inkoper moet je goed weten wie je belangrijkste stakeholders zijn en hoe je daar mee om gaat en hoe je die kan overtuigen. Het andere deel is keuzes maken en kijken naar data. Data kan je helpen om beslissingen te maken, om te reflecteren op je beslissingen of kan je heel erg helpen in je onderhandelingen met je leverancier. Maar data is ook een valkuil als je niet weet waar je naar kijkt of alleen de dingen gebruikt die je vermoeden bevestigen. Zoals Arthun Conan Doyle in Sherlock Holmes al schreef: “It is a capital mistake to theorize before one has data. Insensibly one begins to twist fact to suit theories, instead of theories to suit facts”. In dit stuk presenteer ik drie tips die je helpen om naar data te kijken.
1. Welke data wordt gebruikt om dingen aan te tonen (en welke vergeet je)?
Eén van de dingen waar ik data voor gebruik is om aan leveranciers te laten zien hoe hun verkoopcijfers bij mijn opdrachtgever zich de afgelopen jaren hebben ontwikkeld. Dit kan erg helpen in je onderhandeling als je wilt laten zien dat je ondanks dat je twee keer zoveel inkoopt als een jaar geleden wel hetzelfde bent blijven betalen. Het is dan wel belangrijk dat je alle data meeneemt. Stel je laat de leverancier zien dat hun omzet bij jou de afgelopen jaren sterk is gegroeid, kan dat tegelijkertijd nog wel betekenen dat de vier jaar daarvoor de omzet juist heel hard is gedaald. Andersom is het dus ook erg belangrijk om kritisch te zijn als je data ziet. Laat de data die degene tegenover je wel echt zien wat je wilt zien? Zijn er dingen vergeten? Zo kan de groeiende omzet van een bedrijf in een grafiek er erg mooi uit zien, maar als de winst door slecht kostenmanagement niet meegroeit, geeft dat toch een verkeerd beeld.
Een mooi voorbeeld van welke data je niet en wel gebruikt is de survivorship bias in de Tweede Wereldoorlog (zie afbeelding onder deze alinea). Een groot probleem was de hoeveelheid vliegtuigen die neerstorten door luchtafweergeschut, zelfs nadat het leger de vliegtuigen extra had verstevigd op naar hun mening kritieke onderdelen. Het leger keek naar de vliegtuigen die terugkwamen van het front en maakte patronen van waar de meeste kogelgaten zaten. Het idee was om de vliegtuigen daar extra te beschermen zodat er minder vliegtuigen zouden neerstorten. Toen dit probleem werd voorgelegd aan een groep statistici, zagen zij dat er alleen werd gekeken naar de vliegtuigen die terugkwamen en daar waren juist geen kogelgaten te zien in de motoren of de specifieke onderdelen van de staart en vleugels. De vliegtuigen die namelijk daar waren geraakt, waren namelijk niet neergestort en waren daardoor geen onderdeel van de meetgroep.
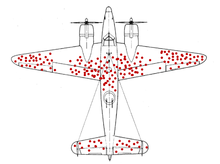
Survivorship bias
2. Waar wordt de data mee vergeleken?
Het is één van de meest voorkomende spreekwoorden en iets wat je (behalve als je fruitboer in de Betuwe bent) zo veel mogelijk moet zien te voorkomen; appels met peren vergelijken. Het is goed om te onthouden dat hoewel data erg belangrijk zijn, dat het uiteindelijk alleen maar cijfers zijn en dat het goed is om te kijken wat er onder die cijfers ligt. Zo kan je de omzet van twee jaren met elkaar vergelijken en hier verschillen tussen zien, maar als je niet goed kijkt wat de precieze reden is hoe de data zo tot stand gekomen zijn, heeft vergelijken niet zoveel zin. Een voorbeeld hiervan is dat veel mensen in het begin van de corona-crisis heel veel vergelijkingen zochten in maatregelen tussen verschillende landen en wat de uitkomst hiervan was op het aantal besmettingen. De werkelijkheid is helaas dat dit veel te complex is en dat er nog een hoop sociale, demografische, geografische en andere oorzaken zijn waardoor twee landen een ander verloop in hun aantal besmettingen laten zien.
3. Causaliteit ≠ correlatie
Data wordt uiteraard vaak gebruikt om te kijken wat de oorzaak van een bepaald gegeven is. Denk bijvoorbeeld aan de stijging van de omzet van een bedrijf en de groei in het aantal medewerkers. Hoewel er een correlatie kan zijn tussen deze twee, wil natuurlijk niet zeggen dat je kunt zeggen dat hoe meer mensen het bedrijf aanneemt hoe hoger de omzet zal zijn. Het kan zijn dat er nog een confounding variabele kan zijn. Een voorbeeld hiervan is dat het kan lijken dat hoe meer gas er in huishoudens wordt verbruikt voor de verwarming, hoe meer warme truien er worden verkocht in kledingwinkels. De confounding variabele is in dit simpele voorbeeld dan natuurlijk de lagere buitentemperatuur.
Het kan ook zijn dat er helemaal geen causaliteit is tussen twee variabelen terwijl er – statistisch – wel een correlatie is. Vaak is dit dan gewoon gebaseerd op een toevalligheid. Een mooi voorbeeld hiervan in onderstaande grafiek. Als we deze grafiek hadden gezien en niet dit interessante artikel hadden gelezen, hadden we wellicht Nicolas Cage verboden om überhaupt nog films te maken.
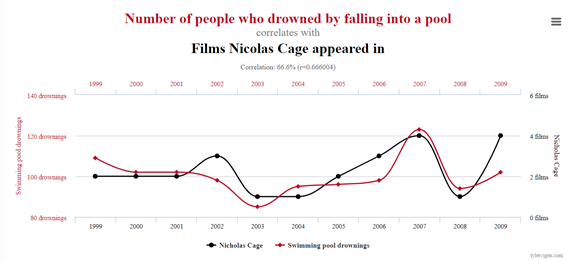
Conclusie
Data is een prachtig iets. Het kan je oorzaak en gevolg laten zien of je laten zien wat je resultaten over een periode zijn geweest. Het laat zien of wat je gedaan hebt ook echt zin heeft gehad. Maar tegelijkertijd is data ook alleen maar een hoop cijfertjes en lijntjes op papier en kan het gebruikt worden door mensen om je te laten zien wat zij willen dat je er in ziet. Daarom is het belangrijk om wanneer je naar data kijkt, goed te kijken wat degene er nou daadwerkelijk mee wil zeggen. Want vaak geldt nog het credo:
There are three kinds of lies: lies, damned lies and statistics
Door Daan de Vries





